
Desenvolvendo com NOSQL -Cassandra em
java – parte 3 Conhecendo Cassandra
No
primeiro e segundo artigo foi introduzido com o conceito de banco de
dados NOSQL suas semelhanças com o banco relacional além de sua
classificação na terceira parte finalmente será falado sobre o
Cassandra . O cassandra é um banco de dados nosql de arquitetura
distribuída, seu armazenamento é configurável (híbrido) e usa o
modelo de família de colunas, o seu projeto foi inciado pela equipe
do facebook e atualmente é mantido pelo apache, foi desenvolvido na
plataforma java. Seu principal case de sucesso é o twitter, facebook
e o Digg. Possui api para as linguagens Ruby, Perl, Scala,
Python, PHP e Java.
Como
o cassandra usa o modelo família de colunas, ele é composto por
keysotre, supercoluna e coluna.
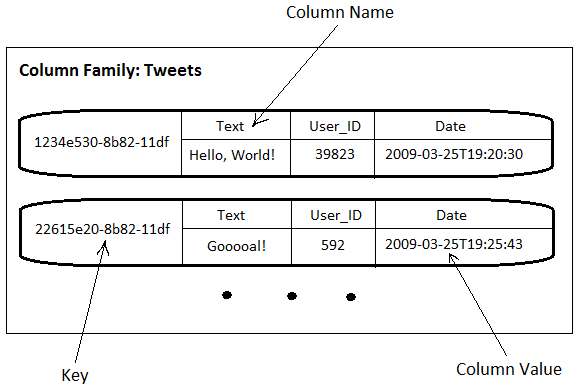
Os tipos de valores que possam ser
ineridos nas colunas são:
- BytesType: tipo simples pelo valor de byte. Nenhuma validação é executada.
- AsciiType: Como BytesType, mas confirma que a entrada pode ser analisado como US-ASCII.
- UTF8Type: Uma string codificada como UTF8
- LongType: Um longo 64bit
- LexicalUUIDType: Um UUID de 128 bits, em comparação léxica (por valor byte)
- TimeUUIDType: a versão 1 UUID de 128 bits, comparados por timestamp
Nível
de Consistência do Casssandra
Para
garantir tolerância a falhas, os dados no Cassandra precisam ser
replicados. O campo timestamp funciona como uma bússola verificando
o campo mais atual entre as replicas. De uma maneira geral o
comportamento de leitura e escrita no cassandra pode ser definida por
apenas três itens:
ONE
(1) - Na escrita, garante que o dado foi escrito em um commit log
e uma tabela de memória de ao menos uma réplica antes de responder
ao cliente. Na leitura, o dado será retornado a partir do primeiro
nó onde a chave buscada foi encontrada. Essa prática pode resultar
em dados antigos sendo retornados, porém, como cada leitura gera uma
verificação de consistência em background, consultas
subsequentes retornarão o valor correto do dado;
QUORUM
(Q) - Na escrita garante que o dado foi escrito em N/2+1
réplicas. Na escrita retorna o valor mais recente lido de N/2+1
réplicas. As réplicas restantes são sincronizadas em background;
ALL
(N) - Garante que operações de leitura e escrita envolverão
todas as réplicas. Assim, qualquer nó que não responda às
consultas fará as operações falharem.
A
tabela 1 e 2 demonstra os níveis de consistência de escrita e
leitura respectivamente.
|
Nível
|
Comportamento
|
|
ANY
|
Garantir
que a gravação foi escrito para pelo menos 1 nó, incluindo
destinatários .
|
|
ONE
|
Garantir
que a gravação foi escrita a pelo menos 1 log réplica cometer e
tabela de memória antes de responder ao cliente.
|
|
QUORUM
|
Garantir
que a gravação foi escrito para N / 2 + 1 réplicas antes de
responder ao cliente
|
|
LOCAL_QUORUM
|
Garantir
que a gravação foi escrito para
|
|
EACH_QUORUM
|
Garantir
que a gravação foi escrito para
|
|
ALL
|
Garantir
que a escrita é escrita para todas as réplicas N antes de
responder ao cliente. Quaisquer réplicas responder irá falhar a
operação.
|
Ler
|
Nível
|
Comportamento
|
|
ANY
|
Não
suportado. Você provavelmente vai querer uma vez.
|
|
ONE
|
Retornará
o registro retornado pela primeira réplica para responder. A
verificação de consistência é sempre feito em um thread em
segundo plano para corrigir os problemas de consistência quando
ConsistencyLevel.ONE é usado. Isto significa chamadas
subsequentes terão dados corretos mesmo que a leitura inicial é
um antigo valor. (Isso é chamado ReadRepair)
|
|
QUORUM
|
Irá
consultar todas as réplicas e retornar o registro com o timestamp
mais recente, desde que tenha pelo menos a maioria de réplicas (N
/ 2 + 1) relatados. Novamente, as réplicas restantes serão
verificadas em segundo plano.
|
|
LOCAL_QUORUM
|
Retorna
o registro com o timestamp mais recente, desde a maioria das
réplicas dentro do datacenter locais têm respondido.
|
|
EACH_QUORUM
|
Retorna
o registro com o timestamp mais recente, desde a maioria das
réplicas dentro de cada datacenter ter respondido.
|
|
ALL
|
Irá
consultar todas as réplicas e retornar o registro com o timestamp
mais recente, uma vez todas as réplicas ter respondido. Quaisquer
réplicas responder irá falhar a operação.
|
Apresentado um pouco sobre o cassandra iniciaremos o processo de instalação e configuração dele, para iniciar baixe-o no site do projeto (http://cassandra.apache.org/). Em seguida basta descompactar e dar o seguinte comando dentro da pasta que foi descompactada:
bin/cassandra -f

Para
executar o cliente dentro da pasta descompacta execute o seguinte
comando:

Conclusão:
No
próximo artigo da série será mostrado um exemplo de implementação
utilizando o cassandra nosql, como citado antes para acessar tais
recursos é utilizado uma api específica que varia por linguagem
além de varia por tipos de nosql, no nosso caso será focado a
linguagem java no Cassandra.
Referências:
Java
Magazine nº 86 Introdução ao nosql
http://escalabilidade.com/2010/03/08/introducao-ao-nosql-parte-i/
Cassandra:
http://cassandra.apache.org/
Nenhum comentário:
Postar um comentário